Your ears are picking up on a difference, but strictly speaking it is less about the degree of voicing and more about the degree of sibilance.
I found another sample of a more run-of-the-mill ふみにじった and have created a audio file comparing it with your sample:
Comparison Audio
Using this audio, I generated a spectrogram with Audacity and manually labeled it here:
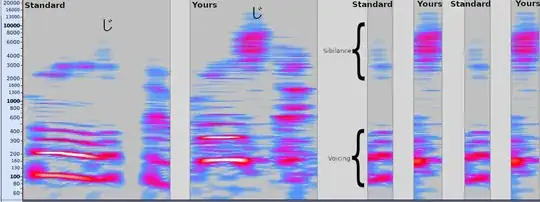
From this we can see that your sample is indeed different, in that it has much louder sibilance: the higher frequencies normally associated with し, generated by air moving quickly between a tight passage between your tongue and roof of your mouth.
But, it has nearly equivalent amounts of voicing: the lower frequencies generated from your vocal chords vibrating.
(One note is that the voicing in yours does seem to end a tiny bit earlier in preparation for the っ, which also likely contributes to what you are hearing.)
Either way, the presence of voicing throughout the majority of the consonant is enough for it to sound like じ as opposed to し to a native speaker in this context.
